
In questo articolo analizziamo insieme come funzionano i motori di ricerca e quali sono le attività che dobbiamo realizzare per posizionare i contenuti del nostro sito sui primi risultati di ricerca.
Partiamo dal presupposto che Google non ha risorse infinite (crawl budget), per questo motivo è fondamentale ottimizzare il nostro sito web affinché google possa rilevare, scansionare ed indicizzare il maggior numero di pagine.
Se sei un Imprenditore, oppure un Direttore Marketing o Commerciale sai perfettamente che è estremamente importante essere primi sulla SERP di Google (elenco dei risultati quando effettuiamo una ricerca).
Essere primi sui motori di ricerca vuol dire incrementare notevolmente le opportunità di vendita dei tuoi prodotti e servizi e la visibilità e notorietà del tuo Brand.
La profondità di Crawling è un tecnicismo che rientra nella Strategia SEO di un’Azienda.
Per raggiungere questo importante obiettivo la nostra Strategia SEO deve tenere in considerazione molteplici fattori:
- Qualità dei contenuti
- Posizionamento SEO dei Competitors
- Parole chiave utilizzate dagli utenti per effettuare le ricerche
- Organizzazione dei nuovi contenuti sul nostro sito (Albero di navigazione)
- Presenza delle parole chiave negli articoli pubblicati sul nostro sito
- Inserimento di link interni al sito per migliorarne la navigabilità (Strategia di link building interna)
- Posizionamento dei contenuti che parlano di noi, su siti di terze parti, che contengono un link verso il nostro sito (Strategia di link building esterna)
Crawler: che cos’è e come funziona il crawling Web
Definizione: Crawler: software o script automatico che ispeziona in modo sistematico le parole chiave, il tipo di contenuto e i collegamenti di un sito web, restituendo le informazioni ai motori di ricerca.
Un crawler – noto anche con il nome di bot, indicizzatori automatici e spider – viene usato dai motori di ricerca per raccogliere tutte le informazioni necessarie per indicizzare in modo automatico le pagine dal Web.
Inoltre i crawler aiutano anche a convalidare i codici HTML e a verificare i collegamenti ipertestuali su ciascuna pagina.
Il primo step che uno spider esegue quando si trova sul tuo sito web è quello di cercare un file chiamato “robots.txt”.
Questo file è di fondamentale importanza, perché contiene tutte le istruzioni per il bot: quali sono le parti del sito web da indicizzare e quali da ignorare.
Crawler google: esempio pratico
Prendiamo come esempio il motore di ricerca Google: il bot analizza ciascuna delle pagine indicizzate nel proprio database e recuperano tali pagine sui server di Google.
Il web crawler segue tutti i collegamenti ipertestuali nei siti web e visita anche altri siti web.
Quando chiediamo al motore di ricerca, per esempio, un “strategia search engine optimization”, avremo come risultato tutte le pagine web che contengono la parola chiave digitata.
Gli indicizzatori automatici sono programmati per scansionare costantemente il Web in modo che i risultati generati siano sempre aggiornati.
Crawling Web: come funziona
Quando parliamo di crawling web (dall’inglese = scansione web), intendiamo quel processo messo in atto da tutti i motori di ricerca, per raccogliere le informazioni dalle pagine di ciascun sito web.
I crawler devono sapere, anzitutto, che il tuo sito web esiste in modo tale che possano passare per dare un’occhiata. Quindi, per eseguire la scansione è necessario un punto d’ingresso.
Se hai creato il sito da poco tempo ti consigliamo di richiedere a Google la relativa indicizzazione.
Se hai realizzato il tuo sito in WordPress ti consigliamo di installare la Plugin Yoast SEO Premium e, tramite Google Search Console, notificare a Google le tue Sitemap.
Una volta che un crawler atterra sul tuo sito web inizia la mappatura di tutti i suoi elementi: dai contenuti ai link in entrata e in uscita, e così via.
Diciamo che, alla fine, tutto ciò che è sul Web verrà trovato e “spiderato”.
Sostanzialmente sono 3 i passaggi che compie un bot:
- Ricerca iniziale e scansione del sito web
- Indicizzazione delle parole chiave e del contenuto del sito
- Mappatura collegamenti ipertestuali (indirizzi pagine Web o URL) che si trovano all’interno del sito
Come gestire la profondità del crawler Google
Quando parliamo di crawling SEO, intendiamo quel processo messo in atto da tutti i motori di ricerca, per raccogliere le informazioni da ciascun sito web.
Mi spiego meglio.
Google, per verificare le informazioni di un sito, utilizza un esercito di ragni (spider, o bots), che vagano per il web con l’obiettivo di catturare le informazioni più rilevanti, a seconda di specifiche parole chiave.
Quindi, per farci trovare dall’esercito a 8 zampe di Google, a questi ragni dovremo dar da mangiare… non credi?
Qui entra in gioco la nostra Strategia SEO, che ci aiuta a scalare la classifica del posizionamento di Google, grazie alle parole chiave e ai contenuti di valore che andremo a realizzare.
Ma andiamo per gradi.
Alla fine di questo articolo ti sarà chiaro il funzionamento del crawling informatica, e potrai utilizzare tutte queste informazioni per migliorare la Strategia per la tua Azienda. Oppure. se preferisci, puoi chiedere una consulenza SEO alla nostra Agenzia.
Crawler Google: la scansione del motore di ricerca
Il crawling web (dall’inglese “scansione web”), è il processo messo in atto dagli spider di Google per visitare una pagina, scaricarla e verificare i collegamenti esterni.
In questo modo, il nostro esercito di ragni ha la possibilità di catturare informazioni aggiuntive, anche dalle pagine correlate grazie alla link building.
Più la nostra pagina sarà in grado di attirare gli spider, più spesso verrà scansionata dai crawler web, alla ricerca di aggiornamenti e modifiche ai contenuti.
Quindi, se nutriamo gli spider di Google costantemente, e con contenuti di qualità, saranno incentivati a tornare da noi.
Al contrario, se tentiamo di sfamarli con “cibo spazzatura”, o contenuti triti e ritriti, si annoieranno presto e cercheranno maggiore qualità altrove.
Parlare di ragni, e dei metodi con il quale sfamarli, spaventa anche me. Però spero di aver reso l’idea.
Come funziona la scansione web?
Come abbiamo detto, i motori di ricerca utilizzano spiders (o bots) per scoprire le pagine web più interessanti, e analizzarle da capo a piedi.
O meglio, dall’header (testata della pagina di un sito) al footer (piede della pagina di un sito).
E questi spiders vengono definiti crawler web.
Per prima cosa, tutti i crawler iniziano la scansione scaricando il file robots.txt.
Questo file è importantissimo, in quanto riporta le informazioni delle sitemap, gli URL, e funge da guida per i motori di ricerca, consigliando quali pagine del sito web scansionare, oppure no.
I processi di crawling, come la maggior parte dei processi web, funzionano tramite uno speciale algoritmo.
Questo serve a stabilire con quale frequenza i crawler web devono scansionare una pagina, e quante (e quali) pagine del sito meritano di essere indicizzate.
Per esempio, una pagina che viene costantemente aggiornata o modificata, ha più probabilità di essere scansionata più volte, rispetto a una sezione che riporta aggiornamenti di rado.
Crawler Google: la scansione di file multimediali (non testuali)
Generalmente, tutti i motori di ricerca tentano di scansionare, e indicizzare, tutti gli URL che trovano lungo il loro cammino.
Tuttavia, se un particolare URL rimanda a un file non testuale, come per esempio un’immagine, un video o un file audio, i crawler dei motori saranno in grado di leggere solo alcuni dati associati a questo tipo di file. Come il nome, o i loro metadati associati.
Ma non diamoci per vinti.
Nonostante i motori di ricerca siano in grado di leggere solo alcune informazioni dei file non testuali, abbiamo comunque la possibilità di indicizzarli, per fare in modo di generare traffico verso il nostro sito.
Scansione ed estrazione dei collegamenti
I crawler spider, scoprono nuove pagine online eseguendo la scansione di un sito web che già conoscono, e delle sue pagine.
Una volta individuati gli internal links delle pagine sottoposte a scansione, procedono all’estrazione dei collegamenti. Per trovare nuovi URL, da cui reperire ulteriori informazioni.
Quindi, utilizzare una strategia di Link Building interna, oltre ad offrire una migliore esperienza agli utenti, visitatori del nostro sito, permette ai crawler internet di reperire sempre più informazioni, rendendo più interessante la nostra pagina ai loro “occhi”.
In questo modo, incentiviamo l’azione degli spider ad eseguire una nuova scansione delle pagine del nostro sito, rendendole sempre più appetibili, e indicizzate, dai motori di ricerca.
Sitemap
La scansione delle sitemap è un’altra tecnica utilizzata dai motori di ricerca per trovare nuove pagine sul web, da cui reperire informazioni.
Le sitemap sono file con estensione .xml che contengono l’elenco dei contenuti da indicizzare del vostro sito.
Sono un ottimo strumento per fornire ai motori di ricerca un vero e proprio elenco delle pagine da scansionare e indicizzare.
All’interno delle sitemap, è possibile includere anche altre pagine del nostro sito, dove per esempio i crawler internet possono trovare contenuti più “nascosti”.
Se il vostro sito internet è sviluppato in WordPress vi consigliamo di utilizzare la plugin Yoast Seo che offre tantissime importanti funzionalità per la redazione dei contenuti nel rispetto delle regole e della vostra Strategia SEO.
Una di queste funzionalità riguarda proprio la creazione ed aggiornamento delle sitemap del sito.
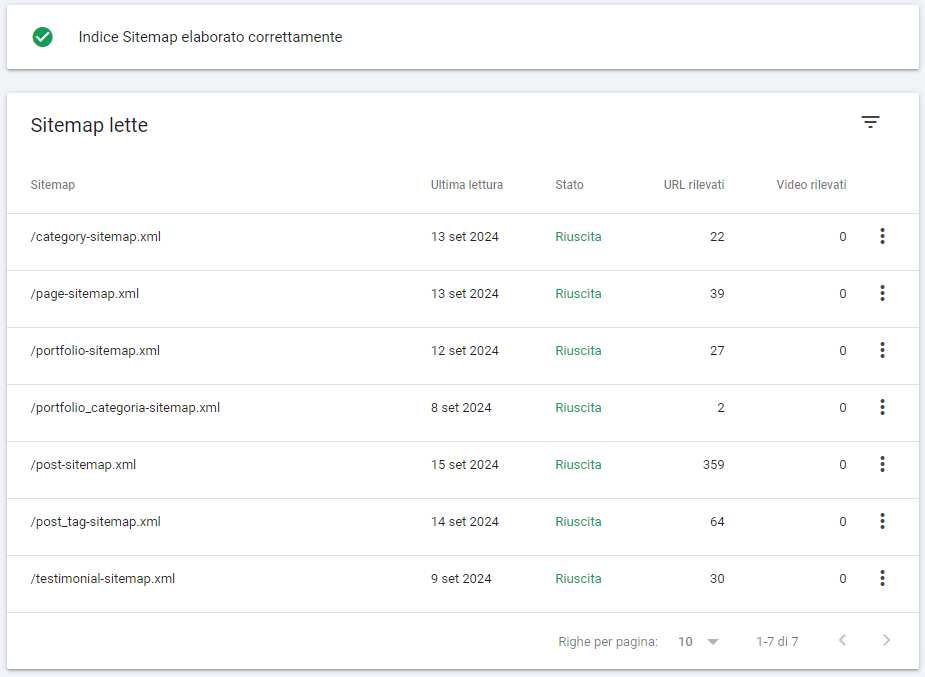
Nell’immagine è riportato l’elenco delle sitemap xml del nostro sito generato direttamente dalla Plugin Yoast SEO. Come potete vedere sono suddivise per tipologia di contenuto, in questo modo Google sa, fin da subito, se una sitemap contiene degli articoli, oppure dei prodotti, tag, categorie etc.
Una volta generate le Sitemap con Yoast Seo è fondamentale notificarle a Google Search Console, il servizio gratuito di Google che ci consente di verificare ed ottimizzare al meglio la strategia SEO del nostro sito internet.
Se non sai come fare leggo il Post del nostro Glossario SEO: Procedura per inviare la Sitemap a Google Search Console
Strumenti da utilizzare per una corretta indicizzazione del sito
Esistono alcuni strumenti online che possono essere di grande aiuto nell’indicizzazione delle nostre pagine web. Noi di Factory Keywords te ne consigliamo alcuni:
- Google Search Console
- SemRush
- Google Analytics
- Google Keyword Planner
Con questo articolo speriamo di aver sciolto qualche dubbio in merito al Crawler Google.
Tuttavia se hai delle perplessità, scrivici nei commenti le tue domande.
Saremo lieti di sciogliere qualsiasi tuo dubbio.
Vuoi approfondire gli argomenti relativi alla SEO? Leggi questi articoli:
- Web content writing: come integra le strategie SEO e Marketing
- Corso SEO & AI Awareness per Imprenditori
- Checklist SEO definitiva per il Tuo E-commerce!
- SEO per Avvocati: la guida completa 2026
- Agenzia SEO specializzata nel posizionamento: come ti aiuta?
- Hosting SEO: l’importanza nella indicizzazione di un sito web
- Add URL: aggiungere url a Google